此系列为Cousera上Standford的Mining Massive Datasets课程学习笔记。 这是该系列的第三篇笔记:Finding Similar Sets
应用介绍 Applications
许多数据挖掘的问题都可以被化为是找相似集的问题,比如: 1. 具有很多相似单词的页面可以被认为是相同的主题.. 2. 找具有相似品味的NetFlix(一家在世界多国提供网路随选串流影片的公司)用户,向他们推荐电影。 3. 实体解析(Entity resolution)
相似文档 Similar Documents
给定一堆文档,比如web页面,找到具有大量相同文字的文档对,可以用来发现: * 镜像站点。应用:网页去重 * 抄袭,包括大量引用。 * 来自不同的站点的相似的文章,比如多家媒体都报道某一事件。
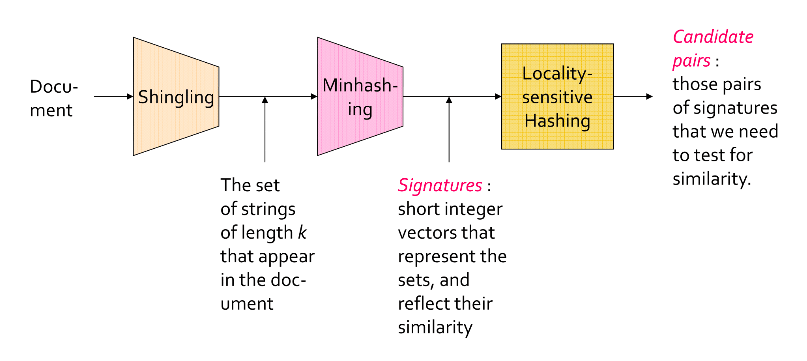
基本技术
- Shingling : 把文档,邮件等等转换成集合。
- Minhashing : 把大的集合转换成短的标志(signature)并且保持着相似性。
- Locality-sensitive hashing : 专注于可能相似的标志对儿(pairs of signature)。
图解
Shingles
k-shingle 或 k-gram 是指文档中连续出现的 k 个字符构成的序列。
举例说明: 给定 k=2 , doc = abcab 。 每两个字符构成一个shingle, 即: ab, bc, ca, ab,所以2-Shingles的集合就为:{ab, bc, ca}
这样就可以用一个k-shingles的集合表示一个文档!
Shingles 和相似度的关系
如果我们发想两个文档中有大量的shingles相同,那么这两个文档就是相似的而且很直观。
如果改变文档中的一个单词,只会影响这个单词前后k个字符的k-shingles。
如果重新把文档中的段落排序,只会影响段落边界周围的2k个k-shingles。
举例说明 k = 3, "The dog which chased the cat" vs "The dog that chased the cat"
第二句把第一句的which改成了that,处理之后之只有7个3-shingles 被替换了,分别是:'g w', ' wh', 'whi' , 'hic', 'ich', 'ch '和 'h c'。
压缩
值得注意的是,如果k取的比较大的话(比如比较论文通常取k=9),shingles会很长,就比较浪费空间了,我们可以把shingles通过hash操作变成一个整数(4个字节),我们管这个整数叫 tokens。之后就可以用一组token来表示一个文档了。
Two documents could (rarely) appear to have shingles in common, when in fact only the hash values were shared.
Minhashing
Jaccard Similarity
杰卡德相似系数
两个集合的Jaccard Similarity定义:交集除以并集。
\(Sim(C_1, C_2) =\frac{ |C_1 \cap C_2|} {|C_1 \cup C_2|}\)
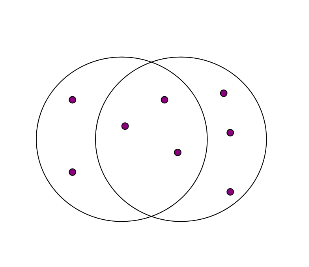
比如上图,两个集合的交集为 \(3\),并集为 \(8\), 所以相似系数为:\(\frac{3}{8}\)
From Sets to Boolean Matrices
把集合转换成布尔矩阵
为了方便计算Jaccard Similarity,我们需要把集合转换成矩阵。
矩阵的行表示集合中的各个元素,比如每个
k-shingles矩阵的列表示各个集合,比如每个文档的
k-shingles集合如果行 \(e\) 是列 \(S\) 的一个成员,那么在\(e\)行\(S\)列的值为\(1\),否则为\(0\)
两列之间的相似度就是Jaccard 相似度。
通常情况下,这会是一个稀疏矩阵。
举个例子 
图中矩阵只有两列\(C_1\)和\(C_2\),他们的相似度就等于都为\(1\)的行除以至少有一个为\(1\)的行,即: > \(Sim(C_1, C_2) = 2/5 = 0.4\)
Four Types of Rows
给定两列\(C_1\)和\(C_2\),我们定义一下四种类型的行: 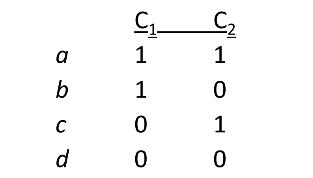
现在可以这么计算Jaccard相似度了:\(Sim(C_1, C_2) = \frac{a}{a + b + c}\)
Minhashing
假设行是随机排列的,定义 \(minhash\) \(function\) \(h(C)\) = the number of the first (in the permuted order) row in which column C has 1 如果没看懂后面有例子。
通常用一些(比如100)独立的hash function来为每列创建\(Signature\)。
这些signatures存储在一个\(signature\) \(matrix\)– whose columns represent the sets and the rows represent the minhash values, in order for that column.
例子
输入矩阵: 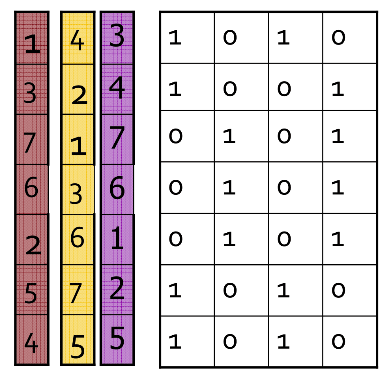
上图右侧为输入矩阵,左侧为3组随机排列。
先看第一组(紫色的) * 排列的第一行是矩阵的第五行,该行第二列和第四列为\(1\), 其余为\(0\), 所以该组的minhash value为0 1 0 1; * 排列的第二行是矩阵的第六行,该行第一列和第三行为\(1\),其余为\(0\),所以minhash value的第二、四行不变,第一、三行改为当前行号,即:2 1 2 1; * 由于每列都非零,这组就结束了,最后的minhash value就是2 1 2 1。
在看第二组(黄色的) * 排列的第一行是矩阵的第三行,该行的第二列和第四列为\(1\),其余列为\(0\),所以minhash value的第二、四列变为当前行号,第一、三列不变,即:0 1 0 1 * 排列的第二行是矩阵的第二行,该行第一、四列为\(1\),其余为\(0\),由于minhash value的第四列值不为0,所以第四列值不变,第一列值变为当前行好,即:2 1 0 1 * 排列的第三行是矩阵的四行,该行第一、四列值为\(1\),而minhash value里的一、四列已不为0,所以没有变化,即还是:2 1 0 1 * 排列的第四行是矩阵的第一行,该行第一、三列值为\(1\),所以minhash value的第三列变为当前行号,其余不变,即:2 1 4 1
第三组留给读者自己练习,总体的标志矩阵(Signature matrix)就是: 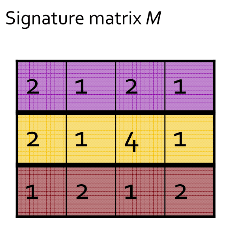
性质
所有排列的\(h(C_1) = h(C_2)\)的概率等于这两列的Jaccard相似度: > \(P(h(C_1) = h(C_2)) = Sim(C_1, C_2)\)
都等于\(\frac{a}{a+b+c}\)!
Why?
\(h(C_1) = h(C_2)\)只有在a类型的行中出现,所以\(h(C_1) = h(C_2)\)这个事件就相当于a类型的行出现,那么\(h(C_1) = h(C_2)\)的概率就是a类型的行出现的概率,即\(\frac{a}{a+b+c}\)。
标志的相似度
- The similarity of signatures is the fraction of the minhash functions in which they agree.
- Thinking of signatures as columns of integers, the similarity of signatures is the fraction of rows in which they agree.
- Thus, the expected similarity of two signatures equals the Jaccard similarity of the columns or sets that the signatures represent.
- And the longer the signatures, the smaller will be the expected error.
Minhash的例子 输入矩阵和上面那个例子相同: 
得到标志矩阵:
我们来计算一下实际的Jaccard相似度与Signature的相似度。
先看第一列和第二列,在输入矩阵中没有\(a\)类型的行,所以Jaccard相似度为零; 在标志矩阵M中第一、二列也没有相同的一行,Signature相似度也为零。
再看第一、三列,输入矩阵中只有一行非\(a\)类型,所以Jaccard相似度为\(0.75\); 而标志矩阵中有两行值相同,一行值不同,所以Signature相似度为\(0.67\)
同理第2、4列的Jaccard相似度为\(0.75\),Signature相似度为\(1.00\)
整理一下: | Similarity | 1-3 | 2-4 | 1-2| | :--- | :--- | :--- | :-- | |Jaccard | 0.75 | 0.75 | 0 | |Signature | 0.67 | 1.00 | 0 |
可见由于排列的组数较少还是有一定误差的。
Minhashing 的实现
困难: * 假设数据量非常大,比如十亿行; * 把十亿行做随机排列是不现实的,也没有必要。 * 不过就算是用之前的随机排列序列,要* 100个随机排列序列,每个序列有十亿个项,光存储这些序列就要大约40TB。 * 随机读取可能会导致系统抖动。
一个好的读取rows实践是准备很多(比如100个)hash function,避免生产序列。
对于每一列 \(c\) 和每个hash function \(h_j\), 只存储一个值\(M(i, c)\)。
目标是让 \(M(i, c)\) 成为每个 \(h_i(r)\) 的最小值, \(h_i(r)\)等于\(r\) where column c has 1 in row r * h i (r) gives order of rows for i th permutation
具体算法
1 | for each row r do begin |
举例: 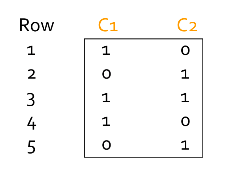
输入矩阵如图所示,取两个hash function : 1
2h(x) = x mod 5
g(x) = (2x + 1) mod 5
具体过程如下: 
最后的结果的相似度的 \(0\), 实际的Jaccard相似度是\(\frac{1}{5}\) ## Locality-Sensitive Hashing 局部敏感哈希
LSH
基本思想:Generate from the collection of all elements (signatures in our example) a small list of candidate pairs: pairs of elements whose similarity must be evaluated.
简单来说就是从我们Minhashing得到的标记矩阵生成可能相似的文档对列表。
候选相似文档对 => 这一对的Jaccard相似度必须被准确计算出来
方法
- 选一个相似度标准 \(t\),并且 \(t < 1\),如果两个文档的相似度大于 \(t\),则认为这两个文档相似。
- 如果列\(c\)和列\(d\)被视为候选文档对,那么他们一定要满足 \(M(i, c) = M(i, d) >= t\) ,其中\(M\)是标记矩阵。
LSH for Minhashing Signatures
总体思想:把标记矩阵里的hash很多遍,只有hash到同一个桶(bucket)里的列才被认为是可能相似的。
Partion Into Bands
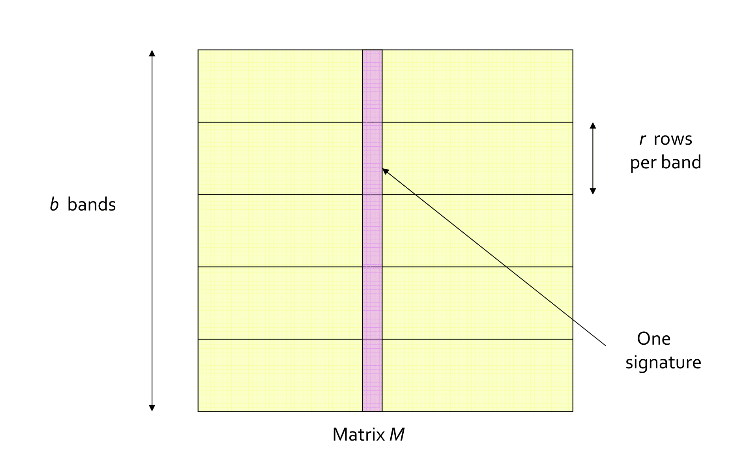
如图所示,把标记矩阵的所有行分成 \(b\) 个带(bands),每个带有 \(r\) 行。对于每条带,对带里面每列进行hash,分别hash到k个桶中,并让k尽可能得大。
只有有>=1的band哈希到同一个桶中,就把这两列当作候选相似对。
Hash Function for One Bucket
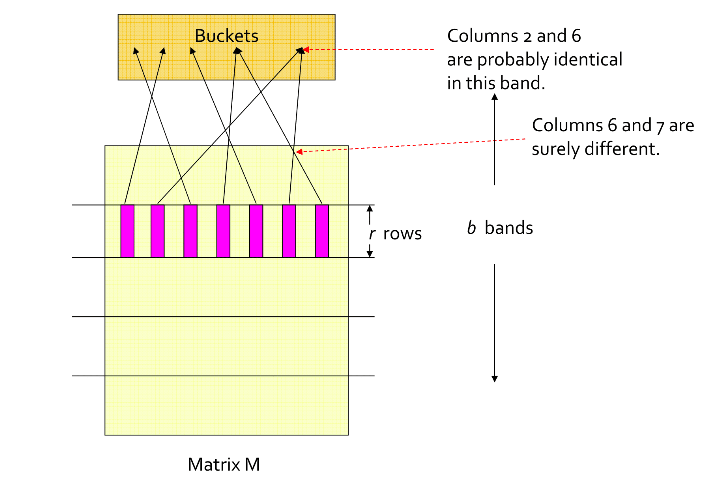
Example - Bands
假设有 100,000 列,每列有100个标记,因此存储标记需要40MB; 我们希望找到所以相似度大于80%的文档对,用上面的方法,把标记分为20个带,每个带里有5个标记。
这样的话,如果文档\(C_1\)和\(C_2\)的相似度是80%,那么他们的任意一个带的5个标记都相同的概率是: \((0.8)^5 = 0.328\) ,看起来好像不大,但是只要有任意一个带都相同就被认为是候选对,所以他们不被选上的概率,即20个带都不相同的概率为:\((1-0.328)^{20} = 0.00035\),也就是每3000个相似度为80%的文档对里才会有一对漏选。
我们再考虑文档\(C_1\)和\(C_2\)只有40%的相似度,那么他们任意一个带的5个标记都相同的概率为 \((0.4)^5 = 0.01\),则文档\(C_1\)和\(C_2\)被选为候选对的概率,即他们中有一个带完全相同的概率为: $C_{20}^1 × 0.01 = 0.2 $,就是说每5个40%相似度的文档对里就有一对会被误选为候选对。但是相似度小于40%的文档对里误选的概率就非常小了。
Analysis of LSH

我们希望LSH达到的效果是相似度在我们设定的阈值之下的文档对都不被选进候选文档对,而在其之上的文档对都选进来,不误选一个也不错选一个,这是最理想的情况,我们的目标就是向它靠拢。
如果不使用分带的方法,直接一行一行的看,会出现下图所示的问题: 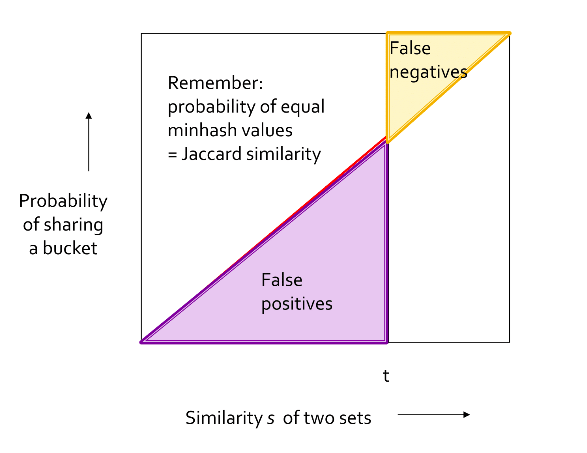
这个图纵向是标记完全相同的概率,横向是相似度,由于相似度等于标记(minhash value)相同的概率,所以实际曲线就是这个矩形的对角线,与理想状况的曲线相差甚远,可见误差是非常大的。
如果把所有行分成b带,每个带有r行,那么曲线如下图所示: 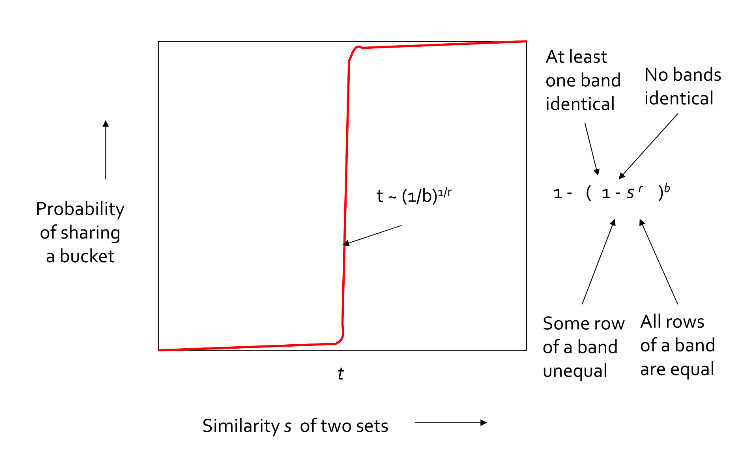
可以得到在阈值 \(t\) 约等于 \((\frac{1}{b})^{\frac{1}{r}}\) 时,曲线与理想状态颇为接近,误差非常小。
数值举例:\(b = 20, r = 5\) 
可见文档相似度在70%以上是很容易被选进的,在40%一下是很难选进的,如果阈值定在70%的话且文档相似度分布比较均匀的和误差会很小。
LSH Summary
Tune to get almost all pairs with similar signatures, but eliminate most pairs that do not have similar signatures.
Check that candidate pairs really do have similar signatures.
Optional: In another pass through data, check that the remaining candidate pairs really represent similar sets . ## Applications of LSH
实体解析 Entity Resolution
实体解析(Entity Resolution)是通过检测记录来判断这些记录是否来自同一个实体。实体可以是人、公司、事件等等。
Typically, we want to merge records if their values in corresponding fields are similar.
Matching Customer Records
这门课的老师曾经应用LSH解决过一个实际问题,这个问题大概是这样:有两个公司A和B,公司A答应把一部分顾客拉拢到公司B,然后B给A一定的费用,一开始挺好,可是好景不长,他们就开始争论到底有多少顾客是从A公司过去的,为此吵得不可开交。
任务就是通过两个公司的数据库判断有多少顾客是从A公司过去的。
注:同一个顾客在两个公司的数据里可能会有一些偏差,比如电话号码变了或者地址变了或者一个用的是小名另一个用的是全名等等。
现状 每个公司大概有1百万条记录描述的顾客可能是被A公司送到B公司的。每条记录包括名字、住址和电话,但是处于种种原因,出自同一个人的记录也可能不完全相同(原因如上)。
方案 1. 定一个量度。比如每对记录有300分的相似度,每个属性100分。两条记录具有相同的地址和电话但是名字拼写有小的差别,这种就给290分,如果名字区别很大可能就是240分等。
- 把经过LSH筛选的所有候选记录的分数算出来,分高的就认为是同一个人。
问题
需要计算 \((1 × 10^6)^2\) 对个分数值,太大了。
解决方法 : A Simple LSH
定义3个哈希函数,分别 hash 名字、地址和电话。如果三个属性有一个是相同的就把具体分数算出来。
这种方法也会丢失一些每个属性的有点小区别的记录对,不过没关系,概率非常小。
额外 > How do we hash strings such as names so there is one bucket for each string? Answer : Sort the strings instead.
指纹匹配 Fingerprint Matching
指纹的存储方法 用一系列细节特征(minutiae)代表一个指纹。 * These are features of a fingerprint, e.g., points where two ridges come together or a ridge ends.
LSH for Fingerprints
把网格铺在指纹上,相同的指纹会重合。具有细节特征(minutiae)的方格的集合就可以表示一个指纹。另外,treat minutiae near a grid boundary as if also present in adjacent grid points.
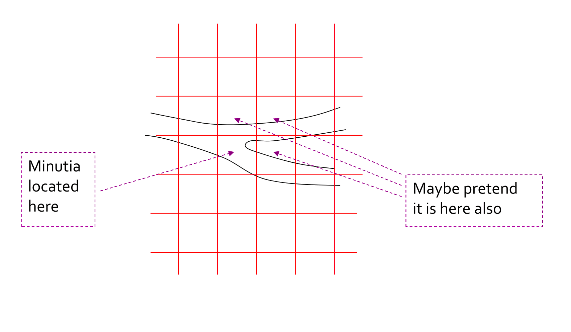
把LSH应用到指纹匹配
- 指纹 = 方格的集合
- 不需要minhash,因为方格数不是很多,而且也不是稀疏矩阵
- 用一个位向量(bit-vector)表示一个指纹:如果那个方格有minutiae,则这个位的值是1。这种方法相对于直接存整数节省了很多空间。
- 随机从位向量中取3个集合,每个集合有3个方格(3位)。
- 对于每一个集合,只有三位全部为1才被认为是Candidate Pairs 。
- Funny sort of ‘bucketization.”
拿一个例子说明算法的效果。
假设 一般的只有有20%的格子有minutiae,如果两个指纹来自同一个手指,那么他们应该有80%的方格是相同的。
计算 任意两个指纹集合在三个格子内都有minutiae的概率为 \((0.2)^6 = 0.000064\)
来自同一个手指的两个指纹集合在三个格子内都有minutiae的概率为 \(((0.2)(0.8))^3 = 0.004096\)
在1024个集合中至少有一个集合满足上述要求的概率为 \(1 - (1 - 0.004096)^{1024} = 0.985\)
不是来自同一个手指但是被选上的概率为 \(1-(1-0.000064)^{1024} = 0.063\),也就是有6.3%的概率误选,并不是很理想,不过我们可以通过增加集合里的方格数,比如变成4或5个,来降低误选率。
Finding Duplicate News Articles
Problem : the same article, say from the Associated Press, appears on the Web site of many newspapers, but looks quite different.
与找相似文档不同的地方在于: * 每份新闻有自己的logo和语言描述 * 不同的广告 * 可能还有到其他文章的链接 * 也可能对原始文章进行了删减
Special Shingling Technique
通过观察可以发现,新闻正文中会出现很多停用词(stop words),然而广告中却没有。
停用词就是没什么实际含义的词,比如: “I recommend that you buy Sudzo for your laundry.” 停用词就是加粗的那些。如果是广告的话可能就只有 “Buy Sudzo” 了。
这个特殊的Shingling就是选停用词以及它后面的两个词作为Shingles,拿上面那就话举例,shingles就是 I recommend that、that you buy、you buy Sudzo等等。
Why it Works
- By requiring each shingle to have a stop word, they biased the mapping from documents to shingles so it picked more shingles from the article than from the ads.
- Pages with the same article, but different ads, have higher Jaccard similarity than those with the same ads, different articles.
Enter LSH
- Their first attempt at minhashing was very inefficient.
- They were unaware of the importance of doing the minhashing row by row.
- Since their data was column by column, they needed to sort once before minhashing.